Olá!
Bem-vindo a postagem que fala sobre a construção de uma super linha-do-tempo de atividades. Em postagens anteriores, vimos como analisar e extrair metadados para diferentes tipos de arquivos. Nesta postagem, irei apresentar timestamps, super timelines, e, em seguida, abordarei log para timeline e também um framework para gerar super-timelines seguido de um exemplo prático em um sistema Windows.
Links de postagens anteriores que servirão de referências aos assuntos dessa postagem:
https://douglasmendes.code.blog/2020/05/21/analise-de-registros-do-windows-analise-forense/
https://douglasmendes.code.blog/2020/06/27/ferramentas-de-analise-de-arquivos-analise-forense/
INTRODUÇÃO AO TIMESTAMPS
Na forense digital, como em todas as ciências forenses, uma das questões fundamentais nas respostas do examinador é quando um ou mais eventos ocorreram. Por esse motivo, a análise de extração de artefatos de tempo (ou timestamps – carimbos de data/hora) relativos a arquivos ou eventos gerados pelos aplicativos do SO, e (ou) usuários desempenham um papel crucial.
Um timestamp (carimbo de data/hora) é um registro que armazena a data e a hora em que um evento ocorreu e pode estar relacionado ao sistema de arquivos com a atividade de um usuário, como o tempo de login ou uma atividade do sistema como a hora em que um serviço foi iniciado e/ou interrompido. Os timestamps podem ser registrados em diferentes formatos (por exemplo):
- O Windows usa principalmente o formato FILETIME, onde os timestamps são armazenados em valores de 64 bits de acordo com o Tempo Universal Coordenado (UTC), mas também usa outros formatos;
- Unix-Linux no formato Posix ou Epoch de 32 bits, que registra o número de segundos desde a zero-hora de 1º de janeiro de 1970.
Em relação ao fuso horário UTC, os carimbos de data/hora (timestamps) são convertidos em datas e horas com base no fuso horário local do sistema. No Windows, o fuso horário local é armazenado na chave do Registro dessa maneira:
- “M” é a hora da última modificação do conteúdo do arquivo;
- “A” é a hora do último acesso ao arquivo;
- “C” é a última hora de alteração dos metadados do arquivo;
- “B” é a hora de criação (nascimento) do arquivo.
Esses dados estão armazenados em $STANDARD_INFORMATION na entrada do MFT (Tabela Mestre de Arquivos – Main File Table).
Os sistemas derivados do Unix geralmente usam os três primeiros atributos de tempo (MAC times), e os armazena de maneira análoga ao Windows, no MFT. E, existe um link para o diretório de fuso horário ( diretório /usr/share/zoneinfo/ ) no diretório /etc/ ( arquivo /etc/localtime ).
Na postagem que fala sobre uma visão geral do Sleuth Kit e da análise do sistema de arquivos que abordamos, o MACtime é uma ferramenta incluída no Sleuth Kit para gerar linha-do-tempo de sistemas de arquivos. Uma linha-do-tempo é uma sequência de eventos, uma ordem cronológica. Criar uma linha-do-tempo do sistema de arquivos é certamente útil, porque nos mostra quando os arquivos foram criados, acessados ou modificados. Mas não podemos confiar apenas nisso.
Por exemplo, alguns sistemas operacionais têm permissão para desabilitar a atualização dos arquivos no último acesso.
- No Windows, por meio da chave de registro HKLM\SYSTEM\CurrentControlSet\Control\FileSystem\NtfsDisableLastAccessUpdate
- No Unix-Linux, por meio da opção noatime da ferramenta mount.
INTRODUÇÃO A SUPER LINHA-DO-TEMPO
Por esses motivos, é mais útil reconstruir o contexto geral no qual os eventos ocorreram. É possível coletar timestamps de diferentes fontes, como sistema de arquivos, registro, sobre logs, conexões de rede, navegador, histórico, etc. que é uma construção chamada super linha-do-tempo das atividades. Por exemplo, uma super linha-do-tempo pode nos dizer que um arquivo malicioso foi salvo e executado por um usuário depois que ele se conectou ao sistema e navegou até uma determinada página da web.
Nesta postagem, abordo um Framework baseado em Python para criar uma super linha do tempo, que é chamada de Plaso, com base na ferramenta log2timeline, uma ferramenta originalmente escrita em Perl por Kristinn Gudjonsson reescrita e incluída no Framework.
SUPER LINHA-DO-TEMPO E PLASO
Log2timeline é composto de analisadores que coleta timestamps de várias fontes e a salva em um arquivo plaso. Log2timeline também pode analisar arquivos de imagem. Outras ferramentas como pinfo e psort estão incluídas no Plaso para filtrar e classificar os dados no arquivo de armazenamento plaso.
O Plaso não é instalado por padrão no Kali Linux (porém é ferramenta padrão do Metapackage Kali-Tools-Forensics). Mas, pensando diferente, resolvi montar essa postagem utilizando o Docker. Então, antes de tudo, segue o passo-a-passo para instalação no Kali.
INSTALAÇÃO DO DOCKER
O primeiro passo padrão de instalação de pacotes utilizando o apt-get é realizarmos a atualização. Então o primeiro comando seria o apt-get update. Na sequência, utilizaremos o comando apt-get –y install apt-transport-https ca-certificates curl gnupg-agent software-properties-common para instalarmos os pacotes básicos.
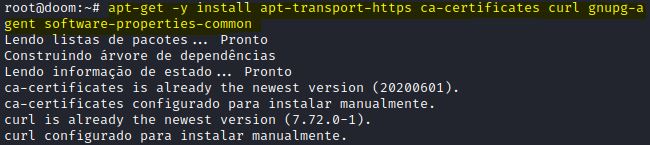
IMAGEM: Do Autor
Segundo passo, digite o comando curl –fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add –

IMAGEM – Do Autor
Terceiro passo, verificamos o fingerprint com o comando apt-key fingerprint 0EBFCD88
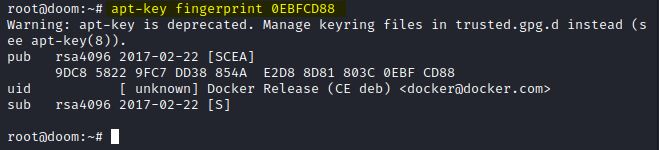
IMAGEM: Do Autor
Quarto passo, digite o comando add-apt-repository “deb [arch=amd64] https://download.docker.com/linux/debian buster stable”

IMAGEM: Do Autor
Quinto passo, instalaremos o “motor” Docker, digitando os comandos:
apt-get update
apt-get –y install docker-ce docker-ce-cli containerd.io
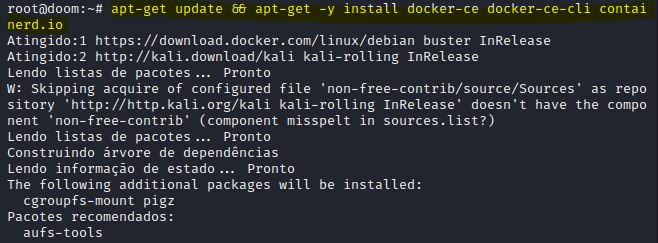
IMAGEM: Do Autor
Feito todos esses passos, para testar se a instalação ocorreu perfeitamente, digite o comando docker run hello-world.
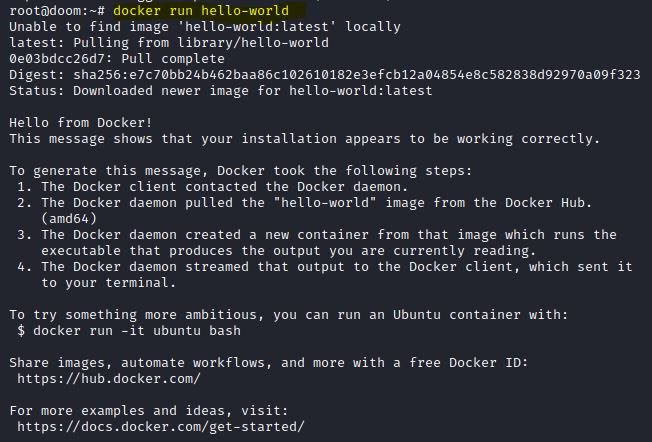
IMAGEM: Do Autor
Para maiores informações, consulte o sitio https://docs.docker.com/engine/install/debian/ .
INSTALAÇÃO DO PLASO NO DOCKER
Passo-a-passo mais curto que esse não existe. Primeiro digite docker pull log2timeline/plaso .
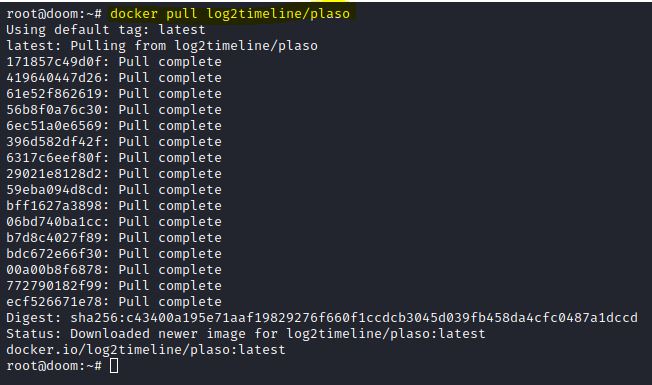
IMAGEM: Do Autor
Agora, para testar se a instalação foi bem feita, digite o comando docker run log2timeline/plaso log2timeline.py –version .

IMAGEM: Do Autor
Maiores informações: https://plaso.readthedocs.io/en/latest/sources/user/Installing-with-docker.html
UTILIZANDO O PLASO – DOCKER
Nesta postagem, criei uma super linha-do-tempo a partir da imagem do Windows já usada para mostrar na postagem do Sleuth Kit. Para utilizarmos pela primeira vez, necessário montar o dispositivo que contém a cópia da imagem para análise no Linux. Para isso, primeiro criei um diretório chamado mount em / com o comando mkdir /mount . Em sequência utilizei o comando fdisk –l para localizar o dispositivo em /dev/ também suas partições, e montei utilizando o comando mount –t ntfs /dev/sdb1 /mount . O nome da partição, e o nome do diretório podem variar. Se atente quando for executar a montagem.
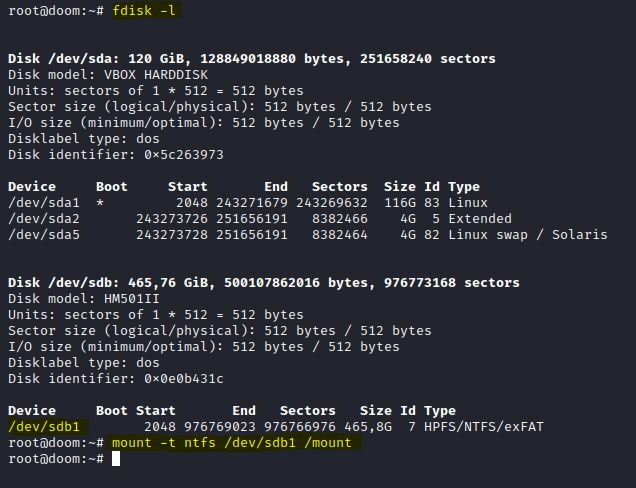
IMAGEM: Do Autor
Feito a montagem, acessei o diretório com o comando cd, e verifiquei qual partição dentro da imagem que iria analisar utilizando o comando fdisk –l {NOME_DA_IMAGEM}.
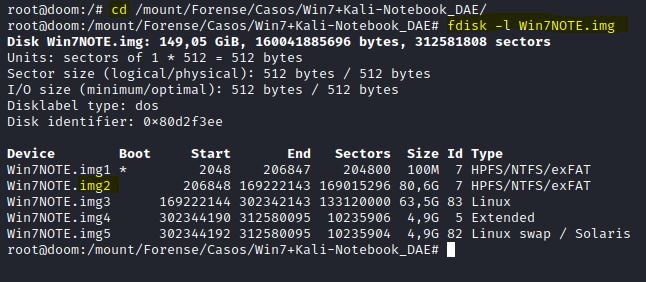
IMAGEM: Do Autor
Agora que sei o local onde a imagem se encontra, e a partição que irei utilizar para concretizar o uso da ferramenta, crio um diretório com o nome plaso dentro do dispositivo com o comando mkdir /mount/plaso, lembrando que pode ser utilizado outro diretório, apenas preferi não utilizar o mesmo que a imagem está.
Seguindo a linha de raciocínio, lembrando que o Docker não reconhece os diretórios externos ao container se não for “avisado”, então deve-se criar uma ponte entre o dispositivo e o container. O comando utilizado para realizar essa tarefa foi docker run –v /mount/:/mount log2timeline/plaso log2timeline /mount/plaso/win7.plaso /mount/Forense/Casos/Win7+Kali-Notebook_DAE/Win7NOTE.img –partitions 2 –f /usr/share/plaso/filter_windows.txt, sendo que:
- docker run –v – Comando para o Docker rodar, com opção selecionada;
- /mount/:/mount – Ponte entre o diretório onde o dispositivo foi montado e o container;
- log2timeline/plaso – O container Docker selecionado;
- log2timeline – Comando evocado;
- /mount/plaso/win7.plaso – Diretório / arquivo .plaso , sendo que uma vez evocado o arquivo é criado automaticamente;
- /mount/Forense/Casos/Win7+Kali-Notebook_DAE/Win7NOTE.img – Diretório / arquivo de imagem;
- –partitions 2 – Número da partição a ser analisada.
- -f /usr/share/plaso/filter_windows.txt – Filtro para análise pré-instalada na aplicação, direcionado para sistemas operacionais Windows. Caso não queira filtrar, apenas ignore essa opção.

IMAGEM: Do Autor
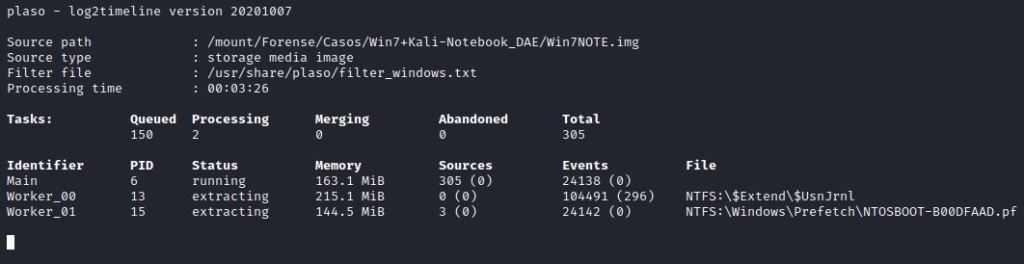
IMAGEM: Do Autor
Aguarde até o processo terminar. Mesmo utilizando filtragem, pode ser que demore dependendo do tamanho da imagem escolhida.
Outra maneira de agilizar o processo é efetuar a análise escolhendo os analisadores (parsers). Para que possa verificar os analisadores do framework, digite o comando docker run log2timeline/plaso log2timeline –info .
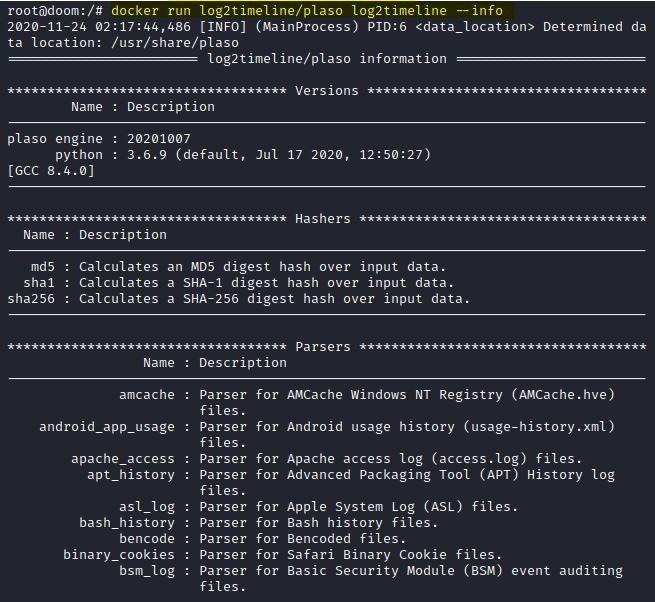
IMAGEM: Do Autor
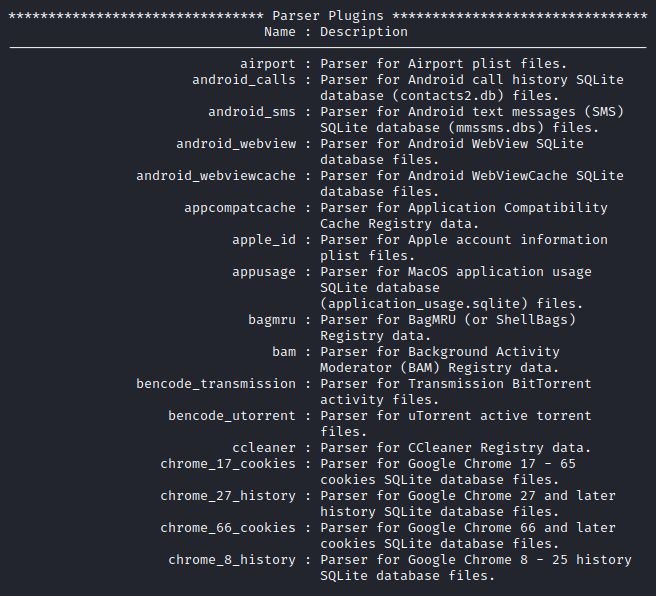
IMAGEM: Do Autor
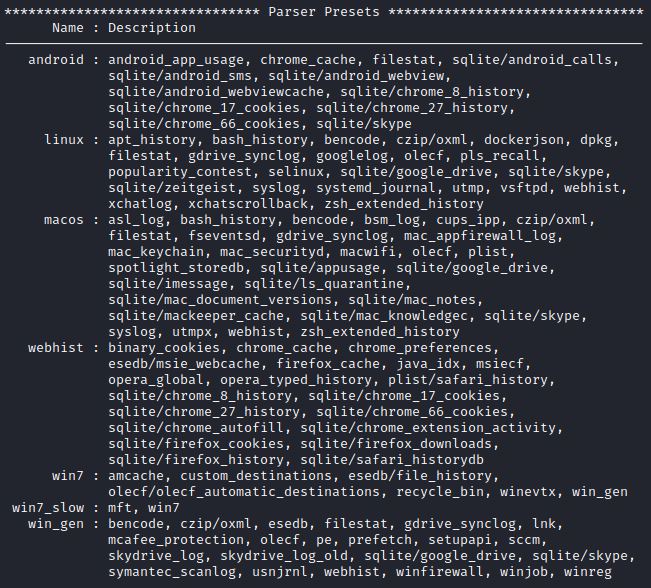
IMAGEM: Do Autor
Um exemplo de utilização seria escolher apenas os analisadores do Windows 7. O comando nesse caso ficou assim:
docker run –v /mount/:/mount log2timeline/plaso log2timeline –parsers “win7” /mount/plaso/win7.plaso /mount/Forense/Casos/Win7+Kali-Notebook_DAE/Win7NOTE.img –partitions 2

IMAGEM: Do Autor
Lembre-se de alterar os nomes de acordo com seu estudo. Outros exemplos de escolha de parsers:
–parsers “win7,\!winreg”
–parsers “winreg,winevt,winevtx”
Agora que temos o arquivo de armazenamento .plaso, podemos obter informações detalhadas sobre ele com a ferramenta pinfo. A sintaxe para execução:
docker run –v /{DIRETORIO_NO HOST}/:/{DIRETORIO_PONTE} log2timeline/plaso pinfo {DIRETORIO/ARQUIVO_.PLASO}
Ou seja, nesse exemplo ficou: docker run –v /mount/:/mount log2timeline/plaso pinfo /mount/plaso/win7.plaso
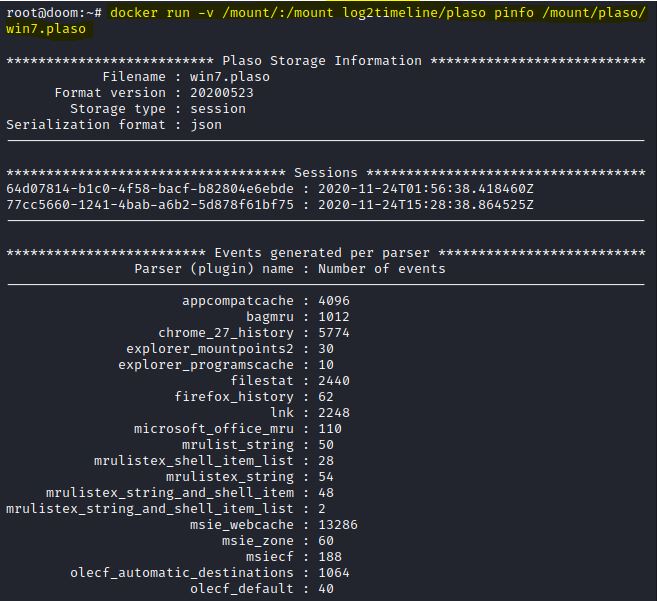
IMAGEM: Do Autor
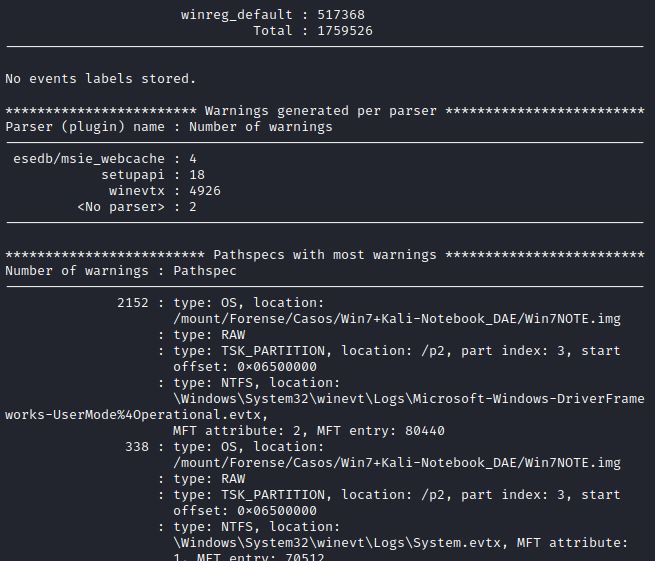
IMAGEM: Do Autor
Este comando retorna informações como o SO detectado, os analisadores usados e o contador de artefatos de timestamps para cada analisador.
O arquivo .plaso não é legível, então temos que convertê-lo com a ferramenta de pós-processamento psort. Podemos converter o arquivo no formato .csv ou .xlsx com essa ferramenta. Devemos especificar a opção de saída com a opção –o, e com a opção -w especificamos o arquivo de saída. Por último, devemos especificar o arquivo .plaso. Como exemplo utilize esse comando:
docker run –v /{DIRETORIO_NO HOST}/:/{DIRETORIO_PONTE} log2timeline/plaso psort –o {XLSX_OU_CSV} -w {DIRETORIO/ARQUIVO_DE_SAIDA} {DIRETORIO/ARQUIVO_.PLASO}
Ou seja, nesse exemplo ficou: docker run –v /mount/:/mount log2timeline/plaso psort –o xlsx –w /mount/plaso/win7.xlsx /mount/plaso/win7.plaso

IMAGEM: Do Autor
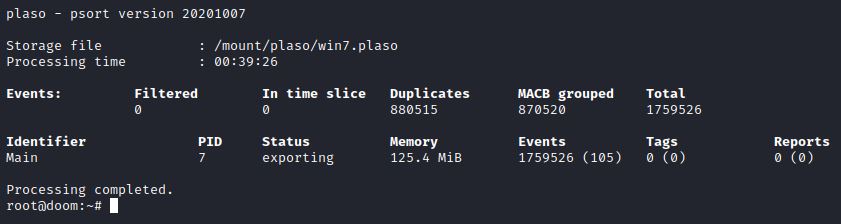
IMAGEM: Do Autor
Podemos analisar o arquivo xlsx usando um programa como o LibreOffice Calc. Cada linha está relacionada a um evento e contém atributos como data e hora, descrição da fonte, usuário, nome e assim por diante. Para tanto, você deve primeiro instalar o pacote LibreOffice com o comando apt-get –y install libreoffice, depois que instalado digitar o comando libreoffice –calc {DIRETORIO/ARQUIVO_XLSX}.

IMAGEM: Do Autor
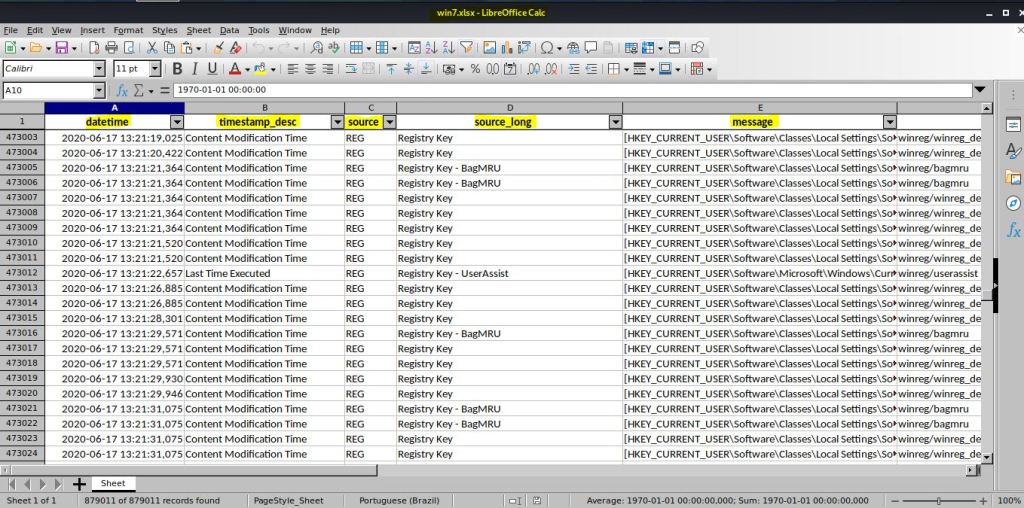
IMAGEM: Do Autor
Como você pode ver, os eventos são ordenados cronologicamente. Como o arquivo xlsx pode ser muito grande para ser analisado manualmente e só podemos estar interessados em alguns dados, também podemos exportar a saída com filtragem de data. Imaginando que os eventos interessantes a análise seriam eventos ocorridos a partir de 2020, pode-se acrescentar a sintaxe o argumento “date > ‘2020-01-01 00:00:00’”, assim como fiz nesse exemplo:
docker run –v /{DIRETORIO_NO HOST}/:/{DIRETORIO_PONTE} log2timeline/plaso psort –o {XLSX_OU_CSV} -w {DIRETORIO/ARQUIVO_DE_SAIDA} {DIRETORIO/ARQUIVO_.PLASO} “date > ‘{ANO-DIA-MÊS_HORÁRIO}’”
Ou seja, nesse exemplo ficou: docker run –v /mount/:/mount log2timeline/plaso psort –o xlsx –w /mount/plaso/win7.xlsx /mount/plaso/win7.plaso “date > ‘2020-01-01 00:00:00’”

IMAGEM: Do Autor
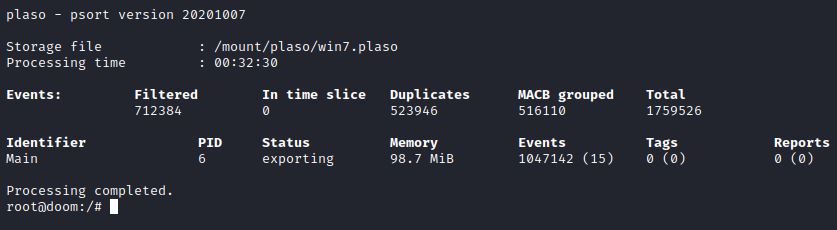
IMAGEM: Do Autor
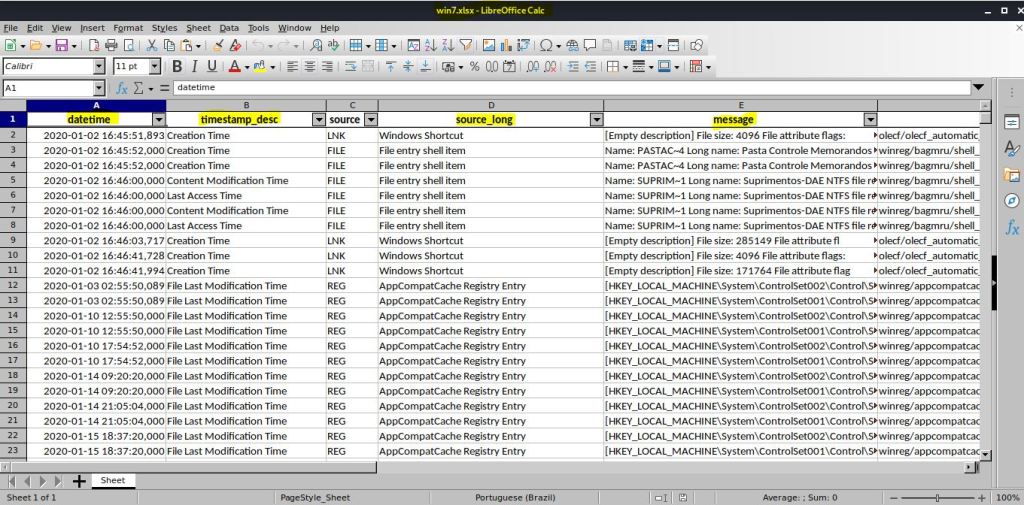
IMAGEM: Do Autor
Da mesma maneira, você pode especificar um intervalo de horas, ou um intervalo de dias, ou a busca de palavras específicas. Montei esse exemplo para deixar bem claro:
docker run –v /{DIRETORIO_NO HOST}/:/{DIRETORIO_PONTE} log2timeline/plaso psort –o {XLSX_OU_CSV} -w {DIRETORIO/ARQUIVO_DE_SAIDA} {DIRETORIO/ARQUIVO_.PLASO} “date > ‘{ANO-DIA-MÊS_HORÁRIO}’ and date <’{ANO-DIA-MÊS_HORARIO}’ and message contains ‘{ARGUMENTO}’ or (filename contains ‘ARGUMENTO2’)”
Ou seja, nesse exemplo ficou: docker run –v /mount/:/mount log2timeline/plaso psort –o xlsx –w /mount/plaso/win7.xlsx /mount/plaso/win7.plaso “date > ‘2020-03-01 00:00:00’ and date < ‘2020-03-01 23:59:59’ and message contains ‘http’ or (filename contains ’history’)”

IMAGEM: Do Autor
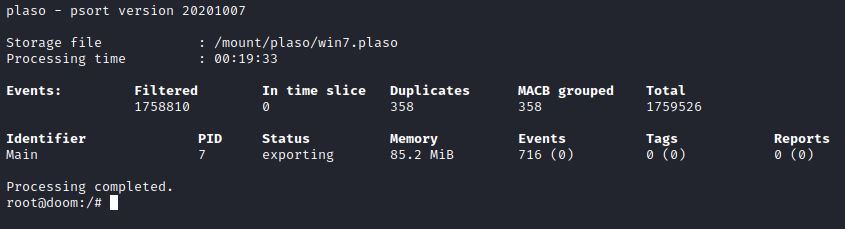
IMAGEM: Do Autor
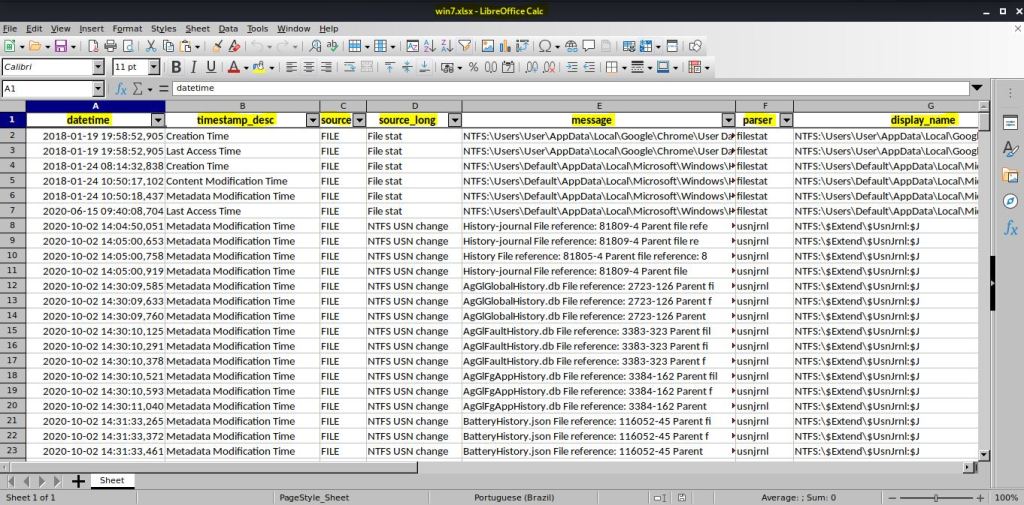
IMAGEM: Do Autor
O resultado da pesquisa criou uma tabela com o que foi solicitado depois de or(…).
Psort também permite aplicar um filtro aos dados de saída. Ele também fornece a opção de “fatiar” a saída, exibindo todos os eventos que aconteceram, por exemplo, de 10 em 10 minutos. O padrão que vem pré-configurado é de 5 minutos. Primeiro, você define com a opção –slice o dia e o horário de início. Depois, com a opção –slice_size o intervalo. Fica desse modo:
docker run –v /{DIRETORIO_NO HOST}/:/{DIRETORIO_PONTE} log2timeline/plaso psort –o {XLSX_OU_CSV} -w {DIRETORIO/ARQUIVO_DE_SAIDA} –slice “{ANO-DIA-MÊS_T_HORÁRIO}” –slice_size ”{MINUTOS}” {DIRETORIO/ARQUIVO_.PLASO}
Ou seja, nesse exemplo ficou: docker run –v /mount/:/mount log2timeline/plaso psort –o xlsx –w /mount/plaso/win7.xlsx –slice “2020-06-01T12:00:00” –slice_size “10” /mount/plaso/win7.plaso

IMAGEM: Do Autor
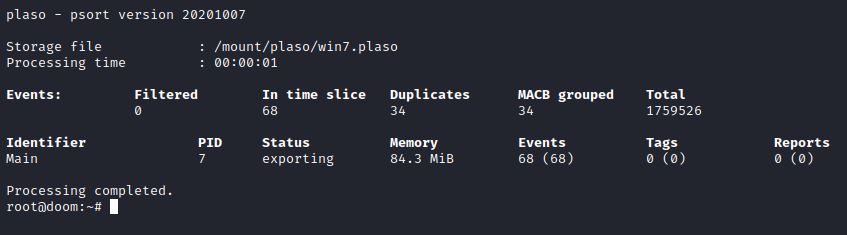
IMAGEM: Do Autor
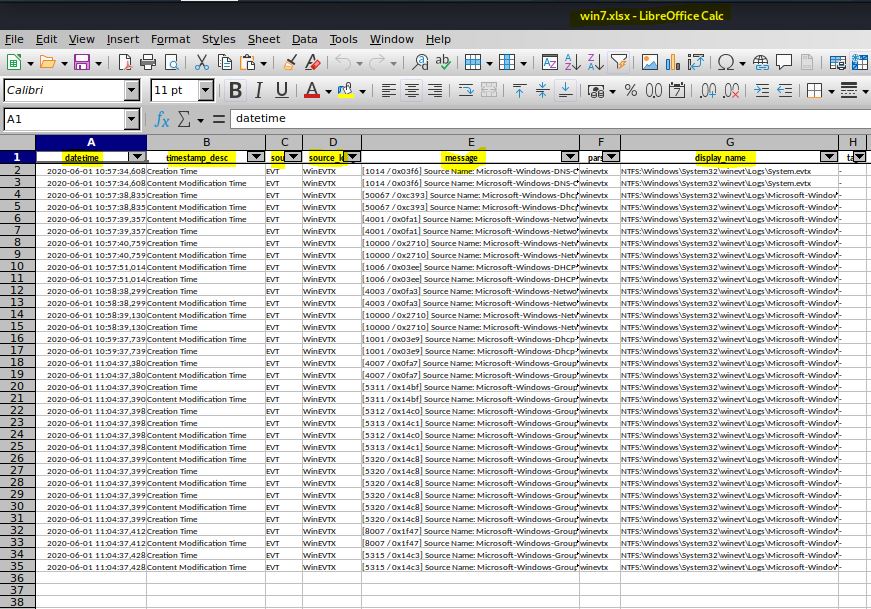
IMAGEM: Do Autor
E, para terminar, você pode também criar a tabela procurando por um nome de usuário específico utilizando “username contains ‘{NOME_DO_USUÁRIO}’” desse modo:
docker run –v /{DIRETORIO_NO HOST}/:/{DIRETORIO_PONTE} log2timeline/plaso psort –o {XLSX_OU_CSV} -w {DIRETORIO/ARQUIVO_DE_SAIDA} {DIRETORIO/ARQUIVO_.PLASO} “username contains ‘{NOME_DO_USUÁRIO}’”
Ou seja, nesse exemplo ficou: docker run –v /mount/:/mount log2timeline/plaso psort –o xlsx –w /mount/plaso/win7.xlsx /mount/plaso/win7.plaso “username contains ‘User’”

IMAGEM: Do Autor
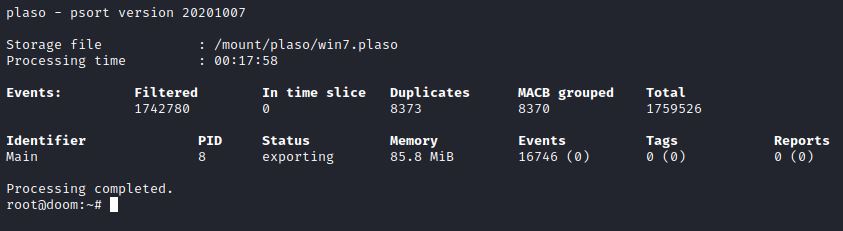
IMAGEM: Do Autor
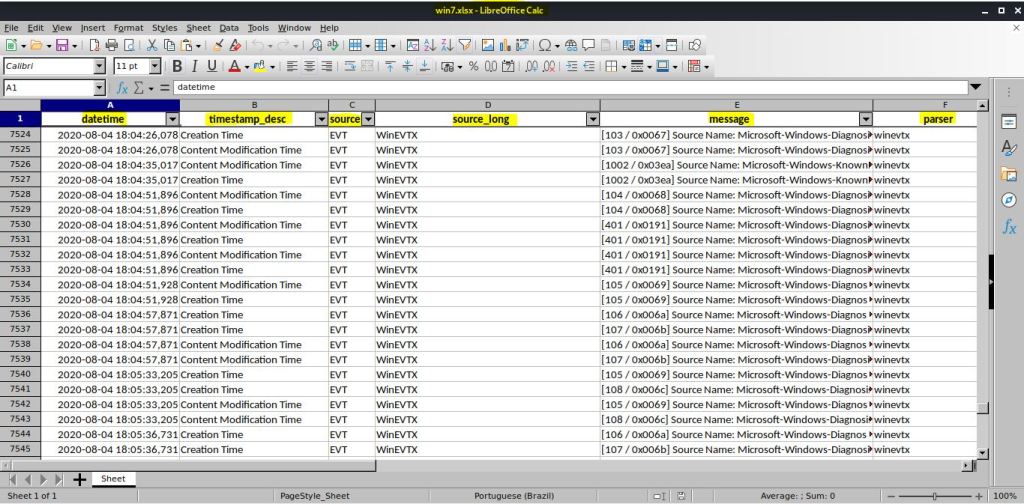
IMAGEM: Do Autor
Mais informações de como utilizar o log2timeline/plaso acesse: https://plaso.readthedocs.io/en/latest/index.html
Beleza! Finalmente terminamos de abordar como construir uma super linha-do-tempo com log2timeline/plaso utilizando Docker. Espero que você possa fazer todas as análises forenses com mais sagacidade com este Framework.
Comente! Deixe seu like!
Até a próxima.

Um comentário em “COMO CONSTRUIR UMA SUPER LINHA-DO-TEMPO DAS ATIVIDADES – ANÁLISE FORENSE”