Olá!
Na postagem anterior, abordamos a extração e análise de artefatos da Internet. Agora, veremos como analisar os arquivos, estabelecendo se são maliciosos ou não, verificando o tipo de dados que eles contêm e extraindo seus metadados em camadas.
Em particular, vamos analisar os arquivos executáveis, de imagem e documento, usando diferentes ferramentas pré-instaladas no Kali Linux.
A análise estática de arquivos é um tópico importante da análise forense digital e fundamental na análise forense de malware. Não vamos nos aprofundar na análise forense de malware nesta postagem, mas precisamos saber pelo menos um pouco ao analisar um arquivo suspeito, se é malicioso ou não.
UTILIZANDO ANTIVÍRUS
Podemos verificar se um arquivo suspeito possui malware utilizando o aplicativo antivírus open source ClamAV. As versões mais antigas do Kali tinham esse AV como padrão. Mas atualmente, com a distro default essa aplicação não vem instalada.
A maneira mais simples para instalar em distros Linux baseadas em Debian é digitando o comando apt-get –y install clamav clamtk clamav-daemon && shutdown –r now , porque há necessidade de reiniciar o sistema para que funcione corretamente. Caso tenha alguma tarefa aberta sem salvar, providencie seu salvamento, ou, se precisar de um tempo, substitua o now pelos minutos que precisa. Por exemplo: 5 minutos = shutdown –r 5. O clamtk instalará a interface gráfica. A imagem abaixo está com o comando incompleto, mas é meramente ilustrativa:
IMAGEM: Do Autor
Após a reinicialização, abra novamente o terminal e digite o comando freshclam para que o AV atualize o banco de dados:

IMAGEM: Do Autor
Agora, vamos executar o ClamAV em um arquivo suspeito. Como encontrei em um HD o programa malicioso KMSpico, que insere códigos de ativação falsos em alguns softwares da Microsoft (software Crack), decidi propositalmente usar o comando clamscan ( clamscan {ARQUIVO OU DIRETÓRIO} ), que faz varredura a procura de malware direcionado nele:
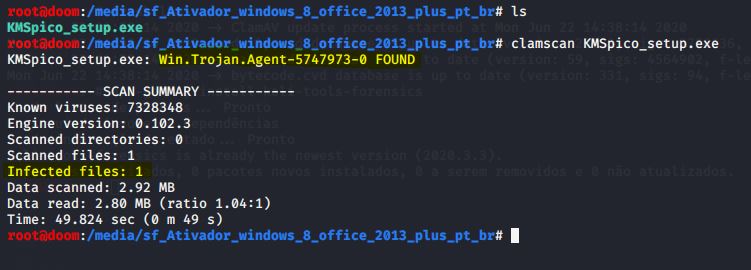
IMAGEM: Do Autor
Nesse caso, clamscan detectou um programa Trojan (Cavalo de Tróia, ou Trojan Horse) preparado para sistema operacional Windows. Caso o ClamAV encontre um arquivo infectado, remova-o usando esse comando:
clamscan –infected –remove –recursive {DIRETÓRIO OU DIRETÓRIOS CONTENDO ARQUIVOS INFECTADOS}
POR EXEMPLO:
clamscan –infected –remove –recursive /root/.cache
Caso for utilizar o comando clamscan em um diretório que contenha além de arquivos outros diretórios-filhos, necessário adicionar a opção –r para que no momento do escaneamento os diretórios-filhos também sejam investigados pelo programa. Senão teremos um escaneamento dedicado apenas aos arquivos desse local escolhido.
Existem muitas opções boas a se estudar digitando o comando clamscan –h. Uso pelo menos duas, tomando um cuidado maior com a segunda:
clamscan –r {NOME DO DIRETÓRIO} –bytecode-unsigned=yes –detect-pua=yes
Da mesma forma, se for para excluir definitivo:
clamscan –infected –remove –recursive –bytecode-unsigned=yes –detect-pua=yes
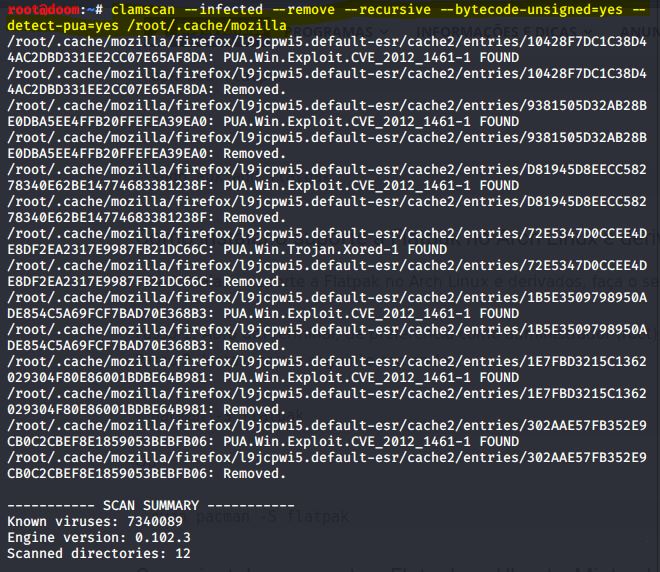
IMAGEM: Do Autor
A função PUA (Potentially Unwanted Applications) pode acusar falso-positivo. Em mãos erradas pode significar a perca do programa deletando ferramentas gerais de sistema. Tome cuidado.
Para inicializar o daemon do ClamAV, digite:
/etc/init.d/clamav-daemon start
/etc/init.d/clamav-freshclam start
Sobre as formas de utilização do ClamAV, aconselho a leitura de seus manuais na página https://www.clamav.net/documents/. Existem outros recursos não expostos aqui.
Para executar a interface gráfica do aplicativo, digite o comando clamtk. Explore suas funções!
IMAGEM: Do Autor
Mesmo que o clamscan não detecte nenhuma ameaça, havendo desconfiança, é melhor não deferir que o arquivo é seguro. Por isso, é melhor enviá-la para um serviço de verificação on-line gratuito, como o virustotal.com. Ele verifica arquivos usando vários scanners de antivírus de forma combinada. Esse serviço tem um limite de tamanho de arquivo de 128mb, mas é suficiente para a maioria dos casos.
IDENTIFICAÇÃO DE TIPO DE ARQUIVO
A análise de arquivos tem duas fases: identificação de conteúdo e extração de metadados. A identificação do conteúdo implica detectar que tipo de dados o arquivo contém.
No Windows, o tipo de arquivo geralmente está associado à sua extensão, que é um sufixo do nome do arquivo com três letras, como .exe, .doc, etc.
Já no Unix – Linux, pode não haver extensões. E, bem, como geralmente não temos extensões, não podemos simplesmente confiar na extensão para determinar o tipo de arquivo. Também, porque alguém pode alterar a extensão sem afetar sua estrutura e conteúdo.
Uma maneira muito mais confiável de identificar um arquivo é por meio do chamado número mágico, que é um valor hexadecimal incorporado no cabeçalho do arquivo. Cada tipo de arquivo possui um número mágico diferente em sistemas derivados do Unix.
Os números mágicos são listados em um arquivo binário compilado. No Kali Linux é /usr/lib/file/magic.mgc:
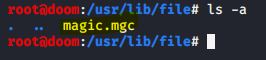
IMAGEM: Do Autor
Para ver uma lista de números mágicos de tipos de arquivos comuns, podemos consultar esta página na Wikipedia:
https://en.wikipedia.org/wiki/List_of_file_signatures
https://pt.qwe.wiki/wiki/List_of_file_signatures (Em Português, mas com anúncios)
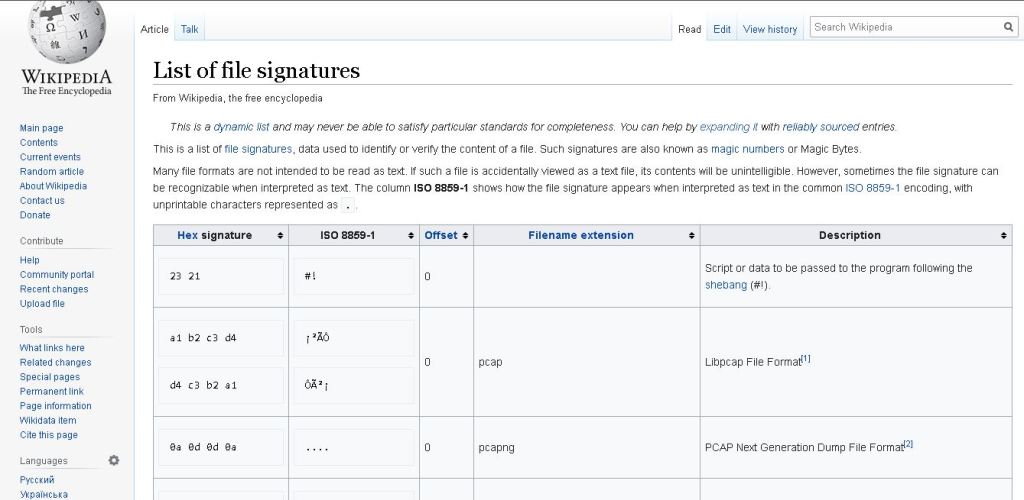
IMAGEM: Do Autor
O Magic File é usado em arquivos pelo Terminal para identificar o tipo de arquivo de verdade.
Por exemplo, copiei renomeando o arquivo malicioso verificado previamente para um outro diretório alterando a extensão .exe para extensão .pdf. Em seguida utilizei dois comandos: ls, para verificar o diretório, e file para verificar o tipo de arquivo analisado.
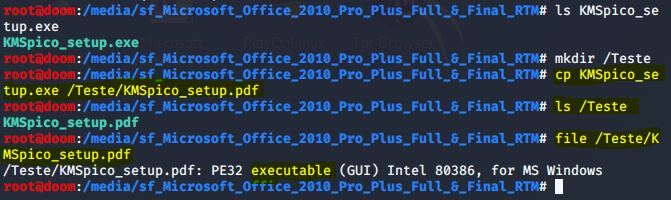
IMAGEM: Do Autor
Em seguida, abri o programa com o comando xxd {NOME DO ARQUIVO} | head :
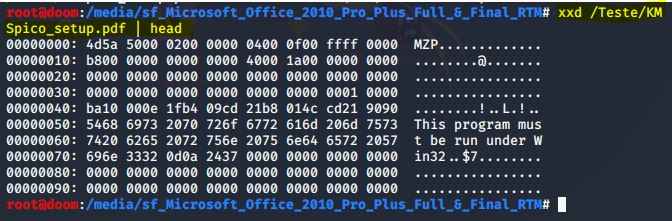
IMAGEM: Do Autor
A primeira coluna na saída representa os deslocamentos. As próximas oito colunas são a representação hexadecimal dos dados. Cada coluna possui dois bytes. E, a coluna do lado direito mostra a representação de texto ASCII.
Podemos ver o número mágico desse tipo de arquivo pdf em dois bytes, que é 4d5a, que corresponde à string MZP à direita. Para provar que alterar a extensão não muda a característica do arquivo, executei o comando no arquivo .exe:
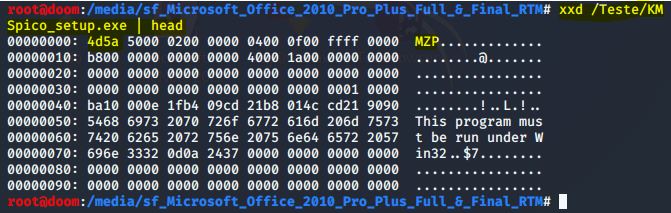
IMAGEM: Do Autor
Pode reparar, que o número mágico e a string são idênticas. Por mais óbvio que seja para alguns, é interessante ter isso fixado em mente.
FIQUE ATENTO: Sistemas baseados em microprocessadores INTEL armazenam informações em little endian. Significa que em alguns casos, os quatro primeiros bytes do cabeçalho deverão ser reordenados para encontrar a correta assinatura do arquivo (magic number). Por exemplo, um arquivo .jpg (ou .jpeg) costuma se apresentar com os bytes d8 ff e0 ff na saída da ferramenta explicada anteriormente, mas na lista de assinaturas de arquivo você encontra a referência em outra ordem: ff d8 ff e0.
Sobre o sistema little endian: No primeiro byte, armazenam-se os bits menos significativos, enquanto, no segundo byte, armazenam-se os bits mais significativos. Isso significa que, por exemplo, se considerarmos que um byte armazene o valor 0x15 e que o byte seguinte armazene o valor 0x74, a word formada por eles será 0x7415. Isso significa que o valor contido nessa word é 29717 e não 5492 (LANGE, 2016).
Um arquivo desconhecido também pode ser identificado com base na Biblioteca Nacional de Referência de Software (National Software Reference Library), baseada no Instituto Nacional de Padrões e Tecnologia (National Institute of Standards and Technology), ou NSRL (NIST), que é um grande banco de dados de hashes de arquivos. O banco de dados pode ser baixado gratuitamente neste link:
Há um programa CLI chamado NSRL query para consultar o banco de dados. Está disponível aqui:
Há também um mecanismo de pesquisa de hash NSRL (NSRL Hash Search Engine) que suporta pesquisas via MD5, SHA-1 ou nome de arquivo, enviando um arquivo por vez. Este mecanismo de pesquisa está disponível neste link:
Outra ferramenta muito útil para análise de arquivos é a ferramenta strings, que também são instaladas em todos os sistemas Linux Unix. Essa ferramenta exibe à força os caracteres imprimíveis vinculados em um determinado arquivo. Aqui, executo strings no mesmo arquivo malicioso, redirecionando a saída para um arquivo de texto:

IMAGEM: Do Autor
Lendo este arquivo de saída, podemos recuperar informações úteis, como as funções Win32API chamadas pelos programas e, eventualmente, você obtém endereços IP.
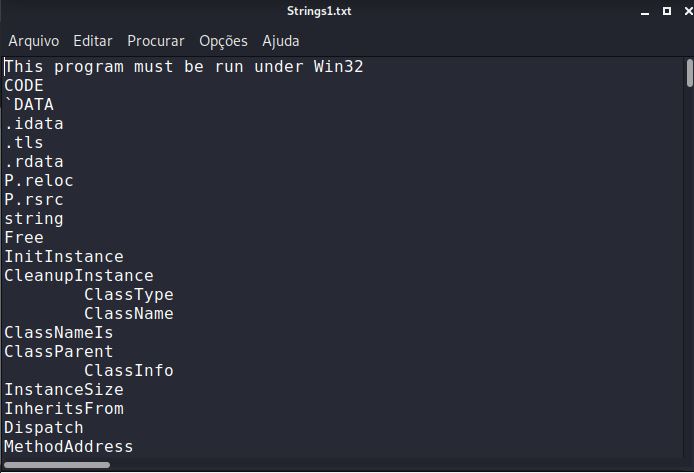
IMAGEM: Do Autor
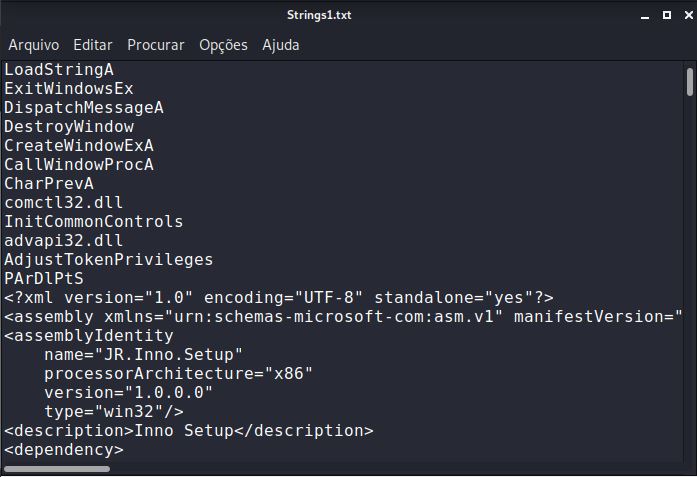
IMAGEM: Do Autor
Também podemos realizar uma pesquisa por palavra-chave ou expressão regular no arquivo de saída usando, por exemplo, o utilitário grep:
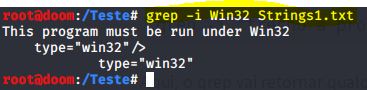
IMAGEM: Do Autor
Ao analisar um sistema Windows, considerando que malwares ou outros arquivos podem não ter uma extensão .exe, podemos encontrar todos os arquivos .exe existentes no sistema sem inspecionar manualmente todos os arquivos. Para fazer isso, uma ferramenta valiosa vem em nosso socorro, identificando esta lista de executáveis em um determinado diretório, chamada missidentify.
Por padrão, o programa relata apenas os nomes de arquivos dos executáveis, dos quais as extensões não correspondem. Algumas extensões executáveis conhecidas são .exe, .dll, .cis, ect …
Neste exemplo, assumo que montei a imagem do Windows que eu usei em postagem anterior sobre análise de registro, na qual executei a ferramenta missidentify no diretório \Windows\System32 especificando a opção -r para também varrer seus subdiretórios recursivamente:
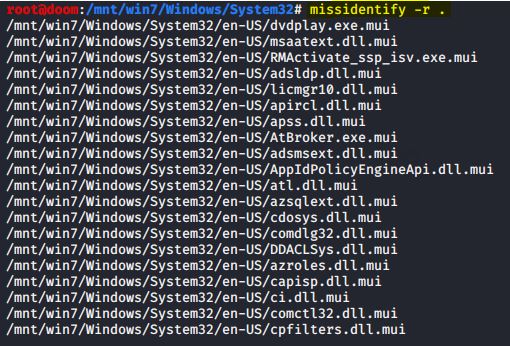
IMAGEM: Do Autor
Como pudemos ver, os arquivos listados não têm uma extensão executável conhecida. Usando no comando a opção -a todos os executáveis serão listados, independentemente de suas extensões.
ARQUIVOS DE IMAGEM E VIDEO
Agora, abordarei a análise de arquivos de imagem e vídeo. Existem muitas imagens e formatos de arquivo de vídeo. Os formatos mais populares são:
- Imagem: JPEG, PNG, BMP, GIF e TIFF.
- Vídeo: WMV, MP4, MOV, AVI e FLV.
Vamos ver como extrair metadados desses tipos de arquivos. Metadados, como já vimos em sistemas de arquivos, ou dados sobre dados.
Nesse caso, os metadados são incorporados no próprio arquivo.
Os metadados mais comuns para arquivos de imagem são o formato de arquivo de imagem intercambiável EXIF desenvolvido para registrar metadados sobre a câmera capturada, como marca, modelo e número de série, configurações da câmera, data e hora e os dados GPS para geolocalização.
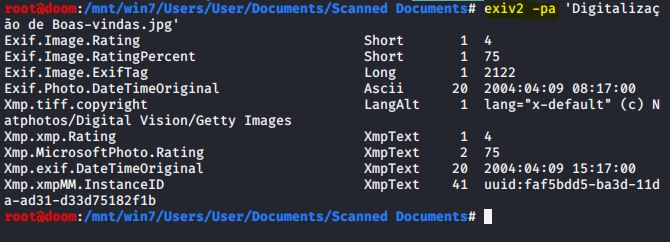
IMAGEM: Do Autor
Exiv2 é uma ferramenta para extrair metadados de arquivos de imagem. O uso é bastante direto, pois fornecemos ao arquivo de imagem a opção -pa para exibir informações mais detalhadas. Eu executei o Exiv2 em um arquivo de imagem .jpg simples. Como pudemos ver, a saída mostra informações de metadados bastante detalhadas sobre a imagem.
Outra ferramenta é poder extrair metadados não apenas da imagem, mas também de vídeo e outros formatos de arquivo comuns, chamada de EXIF TOOL, não instalada por padrão no Kali Linux. Portanto, teremos que instalar o pacote relativo com o comando apt-get –y install libimage-exiftool-perl.
IMAGEM: Do Autor
Executei o EXIFTOOL em um arquivo de vídeo de amostra para examinar seus metadados:
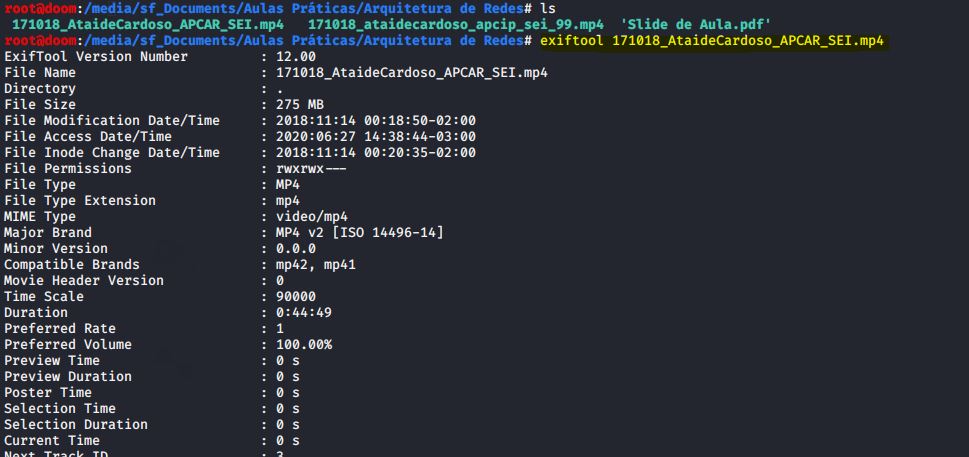
IMAGEM: Do Autor
Os metadados extraídos são semelhantes aos do exemplo anterior, mas específicos ao formato de vídeo, como a taxa de quadros e as propriedades de áudio.
Ao procurar imagens em um sistema Windows, pode ser útil analisar miniaturas e metadados associados. O Windows armazena as miniaturas das imagens de um determinado diretório no arquivo thumbs.db. Mesmo quando as imagens são excluídas, as miniaturas e os metadados persistem em thumbs.db. Este tipo de dados pode ser extraído usando o VINETTO por uma questão de brevidade.
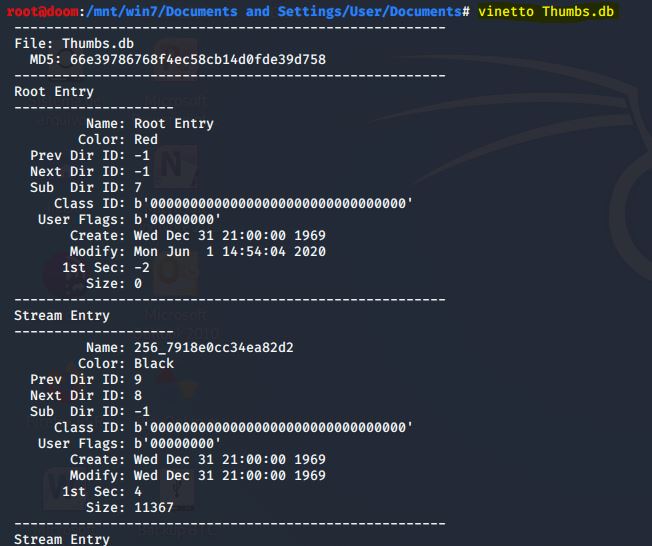
IMAGEM: Do Autor
Suas opções:
IMAGEM: Do Autor
Poderíamos executá-lo especificando o diretório de saída onde armazenar as miniaturas com a opção –o, e a opção -H para gravar um relatório HTML no mesmo diretório de saída.
O Kali Linux também fornece ferramentas para analisar documentos em PDF. Em particular, tanto PDF quanto arquivos do MS Office. Os metadados PDF em formato de arquivo de documento mais populares podem ser extraídos usando a ferramenta EXIF. Eu o executei em um arquivo PDF simples:

IMAGEM: Do Autor
Essa é a saída quando executamos em um arquivo PDF de amostra com as datas de modificação e acesso. A versão em PDF, a contagem de páginas e o programa usado para criá-lo.
Existem também ferramentas projetadas especificamente para analisar PDFs. A primeira que abordo é o PDF ID, que digitaliza o PDF em busca de uma determinada lista de strings e conta as ocorrências. Eu executei o PDF ID no mesmo arquivo PDF utilizado anteriormente:
pdfid {NOME DO ARQUIVO}
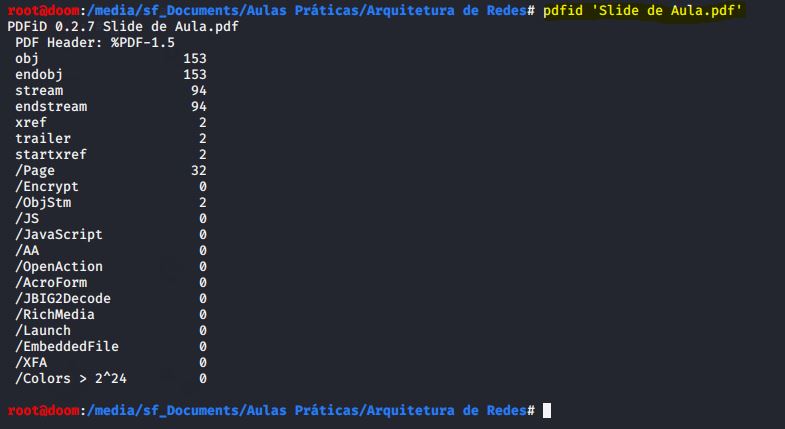
IMAGEM: Do Autor
Ele exibe as ocorrências de seções de código JavaScript no documento. Quando executado em um PDF mal-intencionado, muitas vezes contém código JavaScript, geralmente associado a uma ação automática que o inicia quando o documento é aberto, exibido na saída do PDF ID: /OpenAction. O PDF ID também mostra qualquer código Flash incorporado: /RichMedia.
Outros formatos de documentos muito populares são os do MS Office. O Kali Linux não fornece ferramentas criadas especificamente para analisar esses arquivos. Mas, EXIF TOOL também funciona com esses tipos de arquivos. Podemos executá-lo em um formato de arquivo docx.
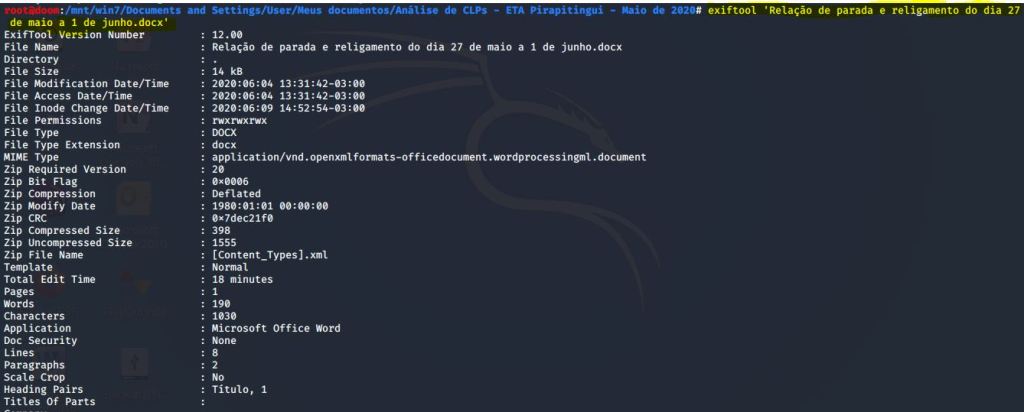
IMAGEM: Do Autor
A saída exibe informações como: o aplicativo usado para criar o documento e o número de páginas, palavras, caracteres, parágrafos, título, assunto, descrição e número de revisões.
Também podemos visualizar os metadados de um documento do office com o libreoffice abrindo o documento com o programa e selecionando File >> Properties
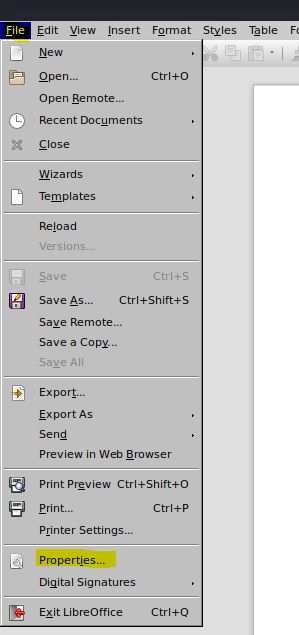
IMAGEM: Do Autor
Com a janela aberta, vasculhe as abas superiores.
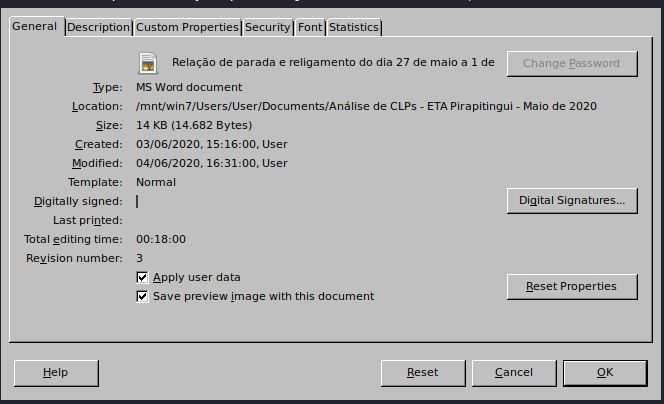
IMAGEM: Do Autor
Beleza! Nesta publicação, vimos como analisar arquivos, estabelecendo se são mal-intencionados ou não, o tipo de dados que eles contêm e extraindo da melhor maneira seus melhores dados. Em particular, analisamos arquivos executáveis, de imagens e documentos usando diferentes ferramentas pré-instaladas ou não no Kali Linux.
Espero que tenha gostado! Comente, e deixe like!
Até breve!

2 comentários em “FERRAMENTAS DE ANÁLISE DE ARQUIVOS – ANÁLISE FORENSE”